Reinforcement learning with snake in pygame
![]()
![]()


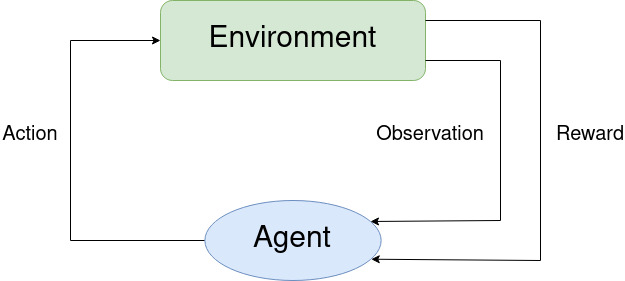
RL building blocks
Agent
The agent is an entity that can enforce actions on the environment and observe changes in it. According to the actions it takes, it is rewarded or punished in the process of training. It’s learning itself through trial and error and receives rewards as unique feedback. In our case the agent is replacing the human player in the process of controlling the snake.
Configurable parameters:
- MAX_MEM - maximal number of sets of states stored for the training
- BATCH_SIZE - size of single batch to train on
- LR - learning rate
Perception
The agent is able to sniff food in 4 main directions - left,up,right,down. Sniffing is based on position of the fruit obtained from the game environment and projected as boolean list of directions.
Environment
The environment consists the table, the apple and the snake.
They provide the information about current state and rewards for the actions
taken by the agent. In our case the environment is represented by following classes:
GameAI, SnakeAI, Fruit and Table. The input for environment is agent’s action
and the outputs are observation and reward for the step or set of steps.
Configurable parameters:
- SCREEN_WIDTH - table width
- SCREEN_HEIGHT - table height
- TICK - how fast should the snake move
- SCALE - how wide the snake should be
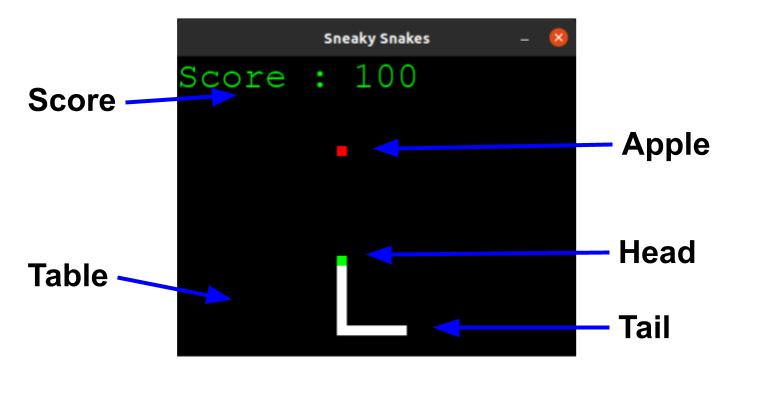
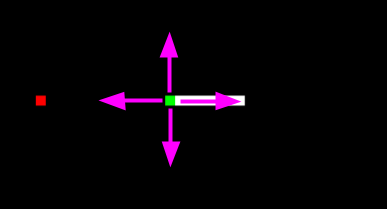
Action
The action is taken by the agent and is affecting the environment,
more specifically the snake’s next move. In our case action is represented as
a list of 0’s and 1’s according to the following schema: [straight, right, left].
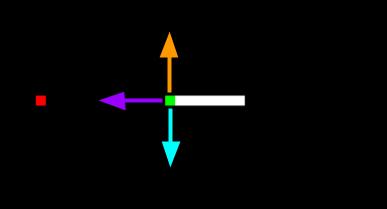
Example:
[1,0,0]means go straight wrt to the snake’s head direction (choosing purple arrow)[0,1,0]means go straight wrt to the snake’s head direction (choosing orange arrow)[0,0,1]means go straight wrt to the snake’s head direction (choosing cyan arrow)
Reward
The reward is assigned based on the performance of the agent in the environment. The agent gets positive reward for getting the apple and negative for hitting walls/himself or exceeding the time intended for exploration.
Neural net model
Used model is fully connected network built of two linear layers.
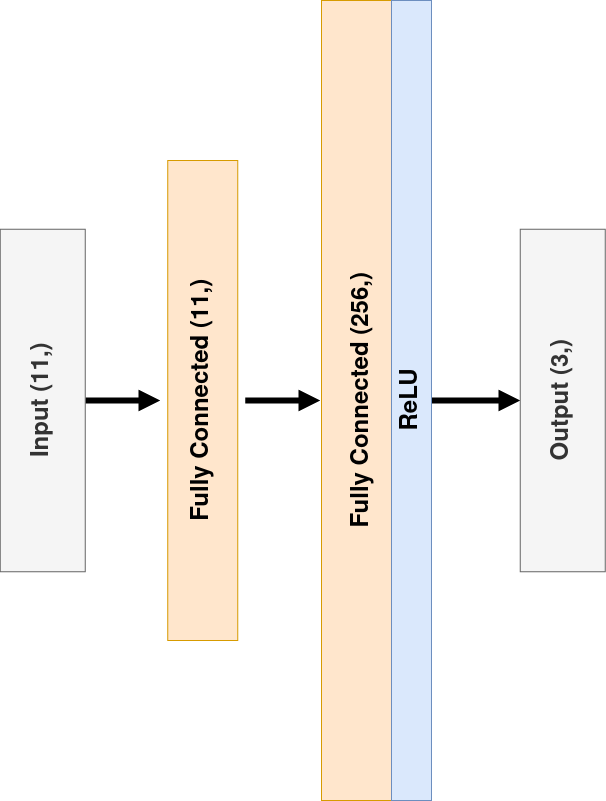
Deep Q-Learning (DQN)
The Deep Q-Learning is using a neural network, in our case a fully connected one,
to approximate, given a state, the different Q-values for each possible action at that state.
We use DQN_Trainer to train the agent with Q-value estimation. We create a loss function
that compares our Q-value prediction for given state and the Q-target, which is the output of
the model in this case.
See more at HuggingFace tutorial
Play around
Prepare python environment
Clone repository:
cd ~/
git clone https://github.com/filesmuggler/sneaky_snakes.git
Create and activate virtual environment in Python
cd sneaky_snakes
python3 -m venv ./snake_env
source ./snake_env/bin/activate
Install packages from requirements into the virtual environment
python3 -m pip install -r requirements.txt
Training
Run command:
python train.py --learning_rate 0.001 --max_mem 100000 --num_games 1000 --batch_size 1000 --width 400 --height 300 --tick 250 --scale 10
The model will be saved at the end of the session into the models directory.
Testing
Run command:
python test.py --model_path "./models/best_model_so_far.pt" --num_games 10 --width 400 --height 300 --tick 10 --scale 10
Bibliography
Coding
- GeeksForGeeks tutorial on creating snake game in Pygame from scratch
- FreeCodeCamp.org tutorial on turning snake into AI project
Theory
- HuggingFace guide on deep Q-Learning